Modeling the Market
A time series sojourn into the S&P 500, with our travel companions Markov chains and Metropolis-Hastings.
Editorial Note: after posting this, with some answers I wasn’t quite sure of but couldn’t find the error, I did notice that my burnoff in the Metropolis-Hastings implementation wasn’t long enough, and as a result day-to-day correlations were too strongly coupled to the initial data point, which was positive growth and, therefore, led to overly rosy estimates of growth. This error has been corrected as of 13 Dec. 2020.
I have a few things I really like thinking about. Food is number one, with travel a close second (at least, pre-COVID, when I could dream of travel). Another is making quantitative predictions, a fourth is knowing how accurate those predictions are, and a fifth is personal finance. So for this project, we’ll take a look at forecasting the S&P 500 and ascribing some variance to those forecasts.
All the code used here, as well as a dataset, is available on my GitHub page.
The S&P 500 — dataset and exploration
The S&P 500 In a Nutshell
People think of investing as picking and buying individual stocks. This is a poor way to invest, as it’s generally accepted that what you really want is to hold a diversity of stocks to reduce the risk on an individual stock tanking. Prior to that, people would create bundles of funds, indexes, to indicate how well the stock market is doing.
The Standard and Poor 500, begun in 1957, is an index that includes a weighted bundle of stocks from the biggest companies by market capitalization. This includes the big tech companies, a few energy companies, Procter and Gamble, big financial institutions like Visa or JP Morgan Chase, etc. The idea is that index measures how the biggest companies in the US are doing, stock-wise. As an investment, it tends to return about 8% per year like clockwork.
What does the data look like?
The first thing we need to do is get the S&P 500 dataset, which we can nab from Yahoo! Finance here. This is a CSV file with dates as well as numeric quantities. When we plot it out, it looks like this

Historical S&P 500 data, viz’d.
This makes it look like not much happened until about 1980, then everything took off, with big booms and busts for the first tech bubble bursting and the subprime mortgage crisis followed by the wild volatility of COVID-19. But the whole 20th century, starting with the Great Depression, is in this plot. We just can’t see it, because of the power of exponential growth.
Visually, exponential growth can be challenging to look at. On this linear scale, the weight S&P 500 value dropping \$300 isn’t that big, but the Great Depression was marked by the S&P 500 dropping from \$300 to basically nothing. When data has an exponential trend, like the stock market (or global population, or a lot of other things), it is usually easier to look at the data on a semilog scale

A semilog plot, where the big tick markets represent a ten-fold increase.
The semilog plot shows a much steadier growth than the exponential. We see the local wiggles. We see the full scale of the Great Depression. We can spot the blips along the way, like the Energy Crisis. There’s a pretty steady rate of growth for almost a hundred years, and fluctuations around that growth.
The semilog analysis is not just nice visually — when fitting a curve to exponentially growing data, the nature of exponential growth means that a simple L2 cost function will punish you far more for getting the most recent data wrong than the early data. We don’t necessarily want that, so when we get to the analysis we’ll actually fit a line to the logarithm of the S&P 500 data.
Analysis of the Dataset
One of the first things we need to do when analyzing time series data is to determine if there’s a trend in the data (check) and, if so, figure out the best way to factor that part out. Once we’ve factored that out, we’ll need to characterize the fluctuations around the trend line, to account for statistical variations in our Markov Chain model.
Fitting the trend line to the data
The first thing to do is fit a trend line to the exponential, which gives us this:

Fitting an exponential line to the logarithmic data.
One thing to notice here is just how much variation was tied to the Great Depression and World War II. If we were to limit ourselves to data after World War II, say around 1945, then the slope of the line would likely go up. The other thing to notice here is how extremely exponential the S&P 500 is — this is very well-modeled by fitting an exponential curve with a doubling time of about 10 years, even with the Dot-Com Bubble bursting, the subprime mortgage collapse, and the Energy Crisis.
The Energy Crisis brings me to another point, which is that if we really want to get into this, we would normalize the values to inflation, since \$10 in World War II is well more than \$10 today. This would be a more detailed economic analysis of the growth of wealth (i.e. purchasing power), but we won’t do that here.
What we might want to ask, then, is how far off from this exponential trend line we can expect the S&P 500 to be in a given amount of time. Therefore, we’d divide the value by the exponential fit value, meaning that 1 means we’re right on target, greater than 1 is outperforming the trend, and less than 1 is underperforming. And here’s what happens when we do that:

The normalized performance of the S&P 500.
This highlights just how huge the drop was in the Great Depression compared to every other economic shock, and also how big the Dot-Com Bubble was. It also highlights how little time the market spends below its expected value compared to above, which suggests that our exponential fit is actually underestimating the growth rate of the market, which as I mentioned before is likely due to the gross over-inflation of the market leading up to the Great Depression distorting the curve fit. This ultimately won’t matter for our model, since any propensity to grow a little faster than the trend line we fit will appear in the model, and the trend line is just fixing a scale. We just happened to pick a scale that's likely useful and keeps everything as a dimensionless parameter on the order of 1, which is handy for building models.
A statistical model of the trend line fluctuations
One thing we notice about this is that there’s a lot of medium-term trends, on the order of a year or two, and a lot of fluctuations at the day-to-day level. This brings me to the core question I’m trying to answer here:
What do those day-to-day fluctuations do to the expected growth over time?
These fluctuations are random, and follow an exponential distribution as we can see here
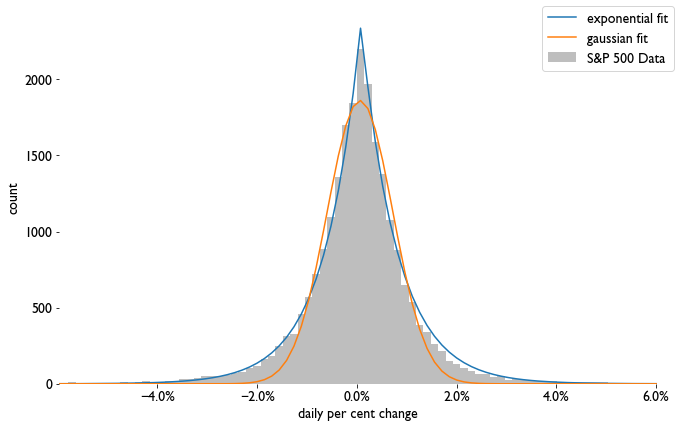
Comparison of a gaussian and exponential fit to the distribution.
Here we fit the popular normal, or gaussian, distribution to the data, as well as an exponential distribution, to show that the percent change on the normalized values are not normally distributed. We’re going to sample from this distribution in the next sections, so we need to make sure we understand it pretty well. If we just slapped a normal distribution fit on the distribution and called it a day, we’d undersample the tails and the almost-no-change days and slightly oversample small changes. This would be wrong, and give us the wrong answer later on.
What is hard to see here is that the average daily percent change is ever so slightly greater than zero — in fact it’s about .08% (which you can find in the Jupyter notebook in the repo). This suggests that the exponential fit is underestimating the average yearly growth percentage by about 20%, i.e. it’s 20% larger than you would naively expect from the curve fitting we did above. This is another indication of just how traumatic the Great Depression was to the economy.
The next thing to look at is day-to-day correlations, because of course the market doesn’t exist without memory — if stocks tanked one day, the next day people are looking for undervalued gems and the market may tend to go up. In fact, when we look at the data of normalized percent change today versus normalized percent change tomorrow, its correlation coefficient is small but negative, suggesting that poor performance one day correlates with better performance the next, and vice versa. The computed correlation matrix is:
$$\left ( \begin{array}{cc} \sigma_{00} & \sigma_{01} \newline \sigma_{01} & \sigma_{11} \end{array} \right ) = \left ( \begin{array}{cc} 1.44 \times 10^{-4} & -1.88 \times 10^{-06} \newline -1.88 \times 10^{-06} & 1.44 \times 10^{-4} \end{array} \right ) $$
Here is a 2D histogram of the distribution:

2D histogram of percent changes today versus tomorrow for the data, which is not completely uncorrelated. The correlations day-to-day are small, but not unimportant.
We know the distribution of stock values in the S&P 500, that it’s correlated but not too strongly, and we have the actual distribution as a histogram. We know it’s basically random atop the exponential trend from these plots, and we know there’s a slight correlation between where the market was yesterday and where it will go today. This suggests that our model for the fluctuations will be best suited with a Markov chain.
Markov Chain Projections of Future Performance
Now that we have the distribution of changes in the S&P 500, we can do an analysis of the scale of market fluctuations off into the future.
This is where we get a little deeper into the math, and describe what a random walk is, what a Markov chain is, and how we will sample from the distribution we computed above to generate our Markov chain model of the S&P 500.
Markov chain models
Sometimes the time series behavior of a system is deterministic, such as systems of ordinary differential equations where if you have infinite precision on the initial conditions and know the differential equations you in principle can compute the behavior out to infinity (or, you know, the system is chaotic and that’s a whole different can of worms, but nevertheless a deterministic can of worms). Other times you might have a time series is a statistical process, with each step being determined by sampling from a distribution — this is what mathematicians call a random walk. A special kind of random walk, where the distribution depends on the previous state attained, is called a Markov chain.
We demonstrated above that the S&P 500 has some fluctuations around a general trend, and that those fluctuations satisfy an exponential distribution. We also showed that those aren’t uncorrelated, and that the distribution of percent changes today are a function of the percent change yesterday (it could go further than that, but we won’t for this exercise).
Mathematically, we have a time series ${\theta_i}$ for some sequence of fractional changes above and below the expected value for the S&P 500, and $\theta_{i+1}$ comes from a probability distribution $P(\theta_{i+1} | \theta_i)$, the probability of getting $\theta_{i+1}$ given the previous value in the series $\theta_i$. We will fit $P$ here using the histogram of change today versus change yesterday we computed above, and will sample from that distribution using the Metropolis-Hastings algorithm.
Sampling from an arbitrary distribution with the Metropolis-Hastings algorithm
There are a number of nice ways to generate random numbers, from closed form methods like Inverse Transform Sampling to constructive algorithms like Rejection Sampling. However, if there isn’t a nice application of Inverse Transform Sampling, or if the probability distribution isn’t easy to normalize for Rejection Sampling, we have to resort to a more generic method. One approach that I like, because it’s easy to implement, generalizes to multi-dimensional data, and has a name that rolls off the tongue nicely, is the Metropolis-Hastings algorithm.
Metropolis-Hastings Algorithm in a Nutshell
The concept behind the Metropolis-Hastings algorithm for sampling random numbers from a distribution comes from a result on Markov chains. I don't want to get into the details of proving why it works, you can read more about that from Greg Gunderson's blog. However, the idea is that, if you know a function
$$f(\theta) \propto P(\theta)$$
for your probability distribution $P$, then the random walk Markov chain sequence generated by the Metropolis-Hastings algorithm comes from sampling from the distribution $P$.
Metropolis-Hastings generates a random number by starting with a seed value $\theta_0$ and a specified jumping function $g(x; y)$. For this particular implementation, I'll pick $g$ to be a normal distribution centered on $\theta_i$. Given $\theta_i$ and the jumping distribution, take a random number sampled from $g(\theta^*; \theta_i)$, and compute the acceptance ratio
$$\alpha = \min \left (1, \frac{f(\theta^\star )}{f(\theta_i)} \frac{g(\theta_i; \theta^\star )}{g(\theta^\star ; \theta_i)} \right )$$
Then, pick a uniformly distributed random number $0 < u < 1$. If $u < \alpha$, then the next term in the Metropolis-Hastings sequence $\theta_{i + 1} = \theta^*$; otherwise $\theta_{i+1} = \theta_i$ and we repeat. The resulting Markov chain sequence ${\theta_i }$ will have a distribution sampled from the probability distribution $P(\theta)$.
Some Notes on the Implementation
A working implementation of Metropolis-Hastings for this application is available in the Jupyter notebook, which you are free to use and modify as you like. I also have a basic implementation in a GitHub Gist, which uses Numba to speed things up and assumes you’re sampling from a fixed distribution, so it’s not quite suitable for this particular application. Numba is great for something like a Markov Chain, where it’s hard not to implement it without a loop in Python, and it can be ten times faster if Numba works for the problem.
Numba isn’t well-suited for this application, though. The primary problem is that Numba has coverage of NumPy, but not full coverage of SciPy. The numba-scipy package gets you part way there, but we are working with a 2D interpolation SciPy object, and Numba has no idea what to do with that. As a result, the Numba code “compiles” but cannot run, and it actually in my experience with this case runs slower than the pure Python loop.
One way we could get Numba to work would be to skip the 2D interpolation SciPy function, which uses interpolating splines, and instead construct a model of exponential distributions (which we have a feel would work okay with this dataset) whose width and mean parameters depend on the previous day’s percent change. This would likely allow us to use Numba, but it would make an assumption about the shape of the distribution I chose not to make this time around.
Therefore, for this particular problem, we don’t use Numba.
With the Metropolis-Hastings algorithm, we also have to be a little careful. The algorithm itself is a Markov chain, whose distribution of steps matches the distribution it is sampling from. However the Metropolis-Hastings Markov chain is also highly correlated. If we were sampling some large number of values from the distribution, this would not be a problem. However, since we need only one value, we want to make sure we aren’t capturing correlations in the Metropolis-Hastings algorithm with our random numbers that aren’t related to our actual distribution. To do this, we use a “burn-off period” in our implementation, to let the Metropolis-Hastings Markov chain walk for a bit and uncorrelate from its seed before we take the last value as our new random number.
With these details done, we can now start to look at what our model says about the growth of the S&P 500 over some time scale.
Predicting the range of S&P 500 growth ratios with a Markov chain model
To model the market’s behavior going into the future, we will randomly sample a daily growth from the distribution we computed above to look at the fluctuations around the exponential trend. This is a statistical process; each set of samples is one instance of a stock market, but it’s probabilistic not deterministic, so we can’t interpret this as the prediction. We have to ask statistical questions of the model — what’s the average growth over time? how large are the fluctuations? To do this, we need to model hundreds or thousands of stock markets and look at the statistics of the outcomes to give an idea of just how much to expect as a return.
A Markov chain takes a series of random steps, based on where you started. This means we can capture daily correlations. For our model, we use the percent change of the normalized value for each step, and multiply them all together to get a final multiplier of the expected value of the S&P 500 relative to the trend line. Here is an example of one result, going out about ten years (about 250 trading days per year)

Example of relative performance to the trend line
This certainly looks like a stock market, and indeed it is — it’s one simulation of the stock market. What we really need to do is run many simulations to get an idea of the average performance, and the scale of uncertainty. So that’s what I did, a thousand times, and this was the result:

The many Monte Carlo simulations of our Markov Chain model
This tells us that the average after 10 years is about double what the trend line we fit would anticipate, with variance. For this measure we use the median prediction, which is very close to 1, and the median absolute deviation to quantify the error. We do this because of the histogram below.

Distribution of outcomes from our Markov Chain model
Because of the long tails, the mean and standard deviation are not great measures of central tendency. The mean growth is 1.3 with standard deviation of .74, but the histogram above suggests that the typical growth factor is more around 1, but with a long tail that can skew the average and standard deviation. For a distribution like this, it may be more valuable to use the median, rather than the mean. The median for the final outcome is about 1.09, and the median absolute deviation is about .56 — we can get a better feel by looking at the cumulative distribution function.

Normalized distribution (blue) and CDF (red)
What the CDF tells us is that about 80% of the outcomes are below a multiplier of about 1.5, and that the long tail skews the computed average, about 1.3, about 30% higher than the median. This is a good example of how you need to look at your distribution carefully before using the usual measures of central tendency to characterize a dataset.
Conclusions
We’ve analyzed the time series data for the S&P 500, a weighted index of high value stocks that is commonly used as an economic indicator (I’m not here to comment on whether it’s a good or complete indicator). We found a nice exponential trend line starting from roughly after World War II. In a moment of bravery, we fit an exponential curve to the whole dataset, including everything before the Great Depression, and looked at the statistical properties of the S&P 500 value normalized to this trend curve. This involved fitting a distribution and using the Metropolis-Hastings algorithm to sample from it to built a Markov Chain Monte Carlo model of the S&P 500. That model tells us that our trend line underestimates the S&P 500 performance, indicating that our bravery was actually foolishness. The code is freely available, so an enterprising reader could see how choosing a start date for the time series data after World War II, say Jan. 1 1946, would affect the results here.